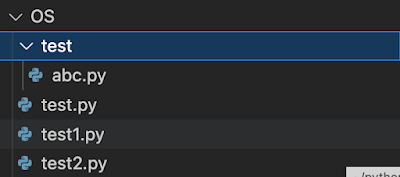
之前還不會用os.walk()時,都是先把檔案集中到單一資料匣下,再用os.listdir()去把檔案列出來。這樣一來就會多一個檔案整理的動作。
1.先來看一下測試時的目錄結構。
2.使用os.walk("目前路徑或其它路徑")去跑一下
import os
for respones in os.walk(os.getcwd()):
print("----------------")
print(respones)
得到的結果
----------------
('/Users/winer406/python/OS', ['test'], ['test1.py', 'test.py', 'test2.py'])
----------------
('/Users/winer406/python/OS/test', [], ['abc.py'])
回傳--> ("路徑","目錄","此目錄下的所有檔案")
3.使用os.walk的另一種呈現方式
import os
for root, dirs, files in os.walk(os.getcwd()):
print("----------------")
print(root)
print(dirs)
print(files)
得到的結果
----------------
/Users/winer406/python/OS <-- 在這個路徑下
['test'] <-- 有1個資料匣
['test1.py', 'test.py', 'test2.py'] <--有3個檔案
----------------
/Users/winer406/python/OS/test <-- 在這個路徑下
[] <-- 沒有資料匣匣
['abc.py'] <-- 有1個檔
4.一次性將檔案的路徑(包含檔案名)列出來,方便做後續的處理
import os
for root, dirs, files in os.walk(os.getcwd()):
for file in files:
fullpath = os.path.join(root,file)
print(fullpath)
得到的結果
/Users/winer406/python/OS/test1.py
/Users/winer406/python/OS/test.py
/Users/winer406/python/OS/test2.py
/Users/winer406/python/OS/test/abc.py
有了絕對路徑,後面要處理檔案就比較方便了
資料參考來源:https://www.ewdna.com/2012/04/pythonoswalk.html